
Navigation menu
 来自Aofeisi量子位的Wenle | QBITAI官方帐户过于扩大...参加比赛的大型模型被取消,每个人都得分0分。 Xie问有关许多顶级模型到底是什么失败的问题? LiveCodeBench Pro:IOI,CodeForces和ICPC竞争水平的实时基准。该银行的问题是每天更新,以防止LLMS“记住问题”。我不得不说,这太残酷了(Doge)。扩展全文
尽管Xie也参加了工作,但她说她只是说她只是啦啦队长。
较早的报告报告说,LLM编程现已超过人类专家,但是该测试的结果表明事实并非如此。
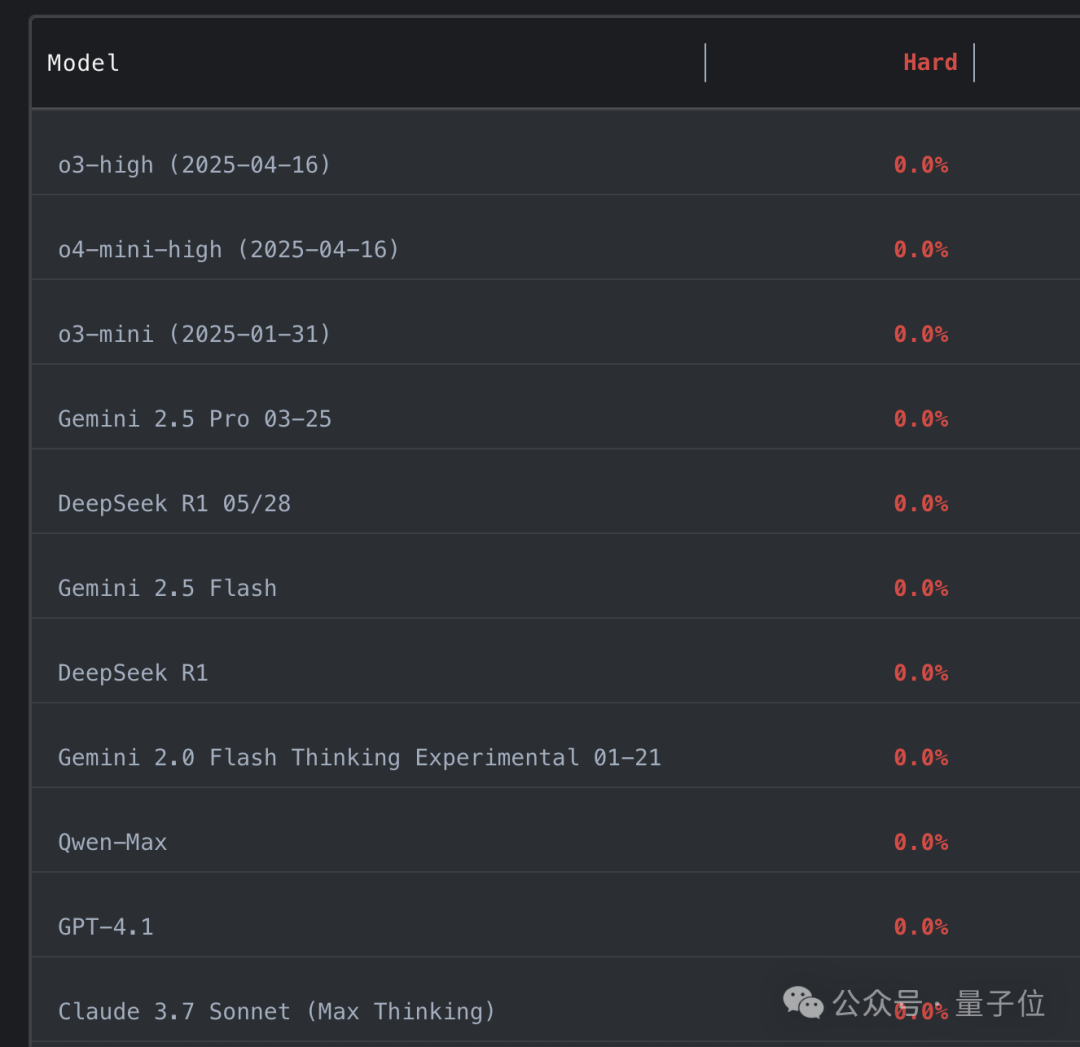
最佳性能模型曾经的过去率仅占中等难题问题的53%,而困难问题的通过率为0。
尽管最佳的O4米尼型型号,一旦呼叫工具被阻止,ELO只有2100,远低于2700个真正的大师的传奇。
Xie Shengning说:
作为这个基准,就像Alphago与Lee Sedol的失败一样。我们尚未达到这个水平 - 即使是有清晰良好结果的问题。
作为这个基准,就像Alphago与Lee Sedol的失败一样。我们尚未达到这个水平 - 即使是有清晰良好结果的问题。
LiveCodeBench Pro:向银行的动态测试,即如何构建LLMS算法的逻辑
基准是由一群奥运会获奖者建造的,收集了每个CodeForces,ICPC和IOI问题,因为比赛的竞赛立即捕获了每个问题,然后在互联网上出现正确的答案之前就捕获了每个问题。
该银行的问题是更新一天,以减少数据污染并确保真实性和环境挑战评估。
该测试包括584个顶级比赛问题。团队已经标记了每个问题。注释内容包括解决每个任务所需的基本技能。问题分开分为三类:根据问题的认知重点,密集知识,逻辑密集型和热情。
这些问题还分为三个贫困水平,这些贫困水平未选择,而是通过正态分布自动选择。
例如,所有标记为2000或向上的CodeForces的问题都将归类为难度。
特定模型的性能
该小组将算法的想法分类为问题,记录了CodeForces难度的官方评级(对应于ELO分数下的50%的成功率),同时详细介绍了主要观察点,常见的陷阱和侧面案例,以提供多维参考。
在测试过程中,团队记录了由模型和人类专家提交的每个解决方案的判断结果(例如通过,错误的答案,时间等),并标记了根本原因(思维级别)错误或错误级别错误)。
如果代码无法p屁股从问题中的样本输入和输出,它标有“样本失败”。
汇编分类和提交问题的结果,比较人类专家的问题解决模式,评估在不同的困难(简单/中/难度)和问题类型(知识/逻辑/逻辑密集型/观察密集型)下的模型性能以及算法推理,样品使用和案例处理中的定位模型。
该团队总共测试了22个大型型号,并提供了完整的性能列表。您可以自己检查每个问题中任何模型提供的解决方案。
同时,绘制了每个模型标记的标记,您可以自由选择要知道的模型。
测试结果显示:
该模型在知识渊博和密集的逻辑问题上发挥更好的作用,并且擅长“旋转记忆”(例如数据结构模板),但在观察或制作案例问题上表现不佳,并且无法处理E“灵感”贪婪的问题和游戏。
与人类相比,诸如O3-Mini之类的模型是GGP表现出更高级的技能准确且没有错误实现,但小于算法设计。
LLM擅长实施问题,但是它们在需要精细算法推理和复杂案例审查的问题上表现不佳,并且经常提供似乎是对但确实错误的解释。
LLMS通常无法正确传递问题提供的输入示例,表明它们不够使用给定信息。
LLM高度取决于工具增强功能(例如终端访问,网络搜索),而不是其自己的推理功能。
该团队还增加了尝试的数量(Pass@k),并发现它可以通过简单的问题显着提高LLM的性能,但他们仍然没有能力抵抗差额的权力。
例如,通过增加O3高模型尝试的数量来尝试其性能,但无论人如何y次测试,它仍然无法解决困难分区的任何问题。
在启用推理功能之后,LLMS通过诸如组合数学之类的密集知识渊博的问题显着改善,但密集观察问题的改善有限。
研究人员还宣布,每个季度,团队将发布全新的审查集,以确保数据及时。
超过一半的团队成员是中国人
Livecodebench Pro团队由一群奥运会冠军组成,其中一半以上是中国成员。
负责该项目的主要人Zheng Zihan毕业于成都外语学校,目前正在纽约大学学习本科学位。他在ICPC世界决赛中代表纽约大学,并获得了第二名。
他曾在Tencent和Nvidia担任实习生和开发实习生,并于今年2月作为实习生进入OpenAI。
另一个负责人Chai Wenhao,2023年在郑安格大学获得了本科学位,并在华盛顿大学学习了硕士学位。今年9月,他将去普林斯顿大学学习博士学位。在计算机科学中。
他曾在亚洲的Pika Labs和Microsoft Research Institute中,他以前的研究主要参与了经常理解和发电模型的视觉效果。
他领导了Moviechat的发展,Moviechat是第一个用于长期视频理解的超大多模式模型。
此外,他发表了有关ICLR,CVPR和ICCV等领先期刊的相关论文研究。
该计划的其他参与者来自加利福尼亚大学,普林斯顿大学等,这是一个非常年轻的团队。
纸张地址:https://arxiv.org/abs/2506.11928
项目地址:https://github.com/gavinzhengoi/livecodebench-pro
兰德列表:https://livecodebenchpro.com/
参考:返回SOHU以查看更多
来自Aofeisi量子位的Wenle | QBITAI官方帐户过于扩大...参加比赛的大型模型被取消,每个人都得分0分。 Xie问有关许多顶级模型到底是什么失败的问题? LiveCodeBench Pro:IOI,CodeForces和ICPC竞争水平的实时基准。该银行的问题是每天更新,以防止LLMS“记住问题”。我不得不说,这太残酷了(Doge)。扩展全文
尽管Xie也参加了工作,但她说她只是说她只是啦啦队长。
较早的报告报告说,LLM编程现已超过人类专家,但是该测试的结果表明事实并非如此。
最佳性能模型曾经的过去率仅占中等难题问题的53%,而困难问题的通过率为0。
尽管最佳的O4米尼型型号,一旦呼叫工具被阻止,ELO只有2100,远低于2700个真正的大师的传奇。
Xie Shengning说:
作为这个基准,就像Alphago与Lee Sedol的失败一样。我们尚未达到这个水平 - 即使是有清晰良好结果的问题。
作为这个基准,就像Alphago与Lee Sedol的失败一样。我们尚未达到这个水平 - 即使是有清晰良好结果的问题。
LiveCodeBench Pro:向银行的动态测试,即如何构建LLMS算法的逻辑
基准是由一群奥运会获奖者建造的,收集了每个CodeForces,ICPC和IOI问题,因为比赛的竞赛立即捕获了每个问题,然后在互联网上出现正确的答案之前就捕获了每个问题。
该银行的问题是更新一天,以减少数据污染并确保真实性和环境挑战评估。
该测试包括584个顶级比赛问题。团队已经标记了每个问题。注释内容包括解决每个任务所需的基本技能。问题分开分为三类:根据问题的认知重点,密集知识,逻辑密集型和热情。
这些问题还分为三个贫困水平,这些贫困水平未选择,而是通过正态分布自动选择。
例如,所有标记为2000或向上的CodeForces的问题都将归类为难度。
特定模型的性能
该小组将算法的想法分类为问题,记录了CodeForces难度的官方评级(对应于ELO分数下的50%的成功率),同时详细介绍了主要观察点,常见的陷阱和侧面案例,以提供多维参考。
在测试过程中,团队记录了由模型和人类专家提交的每个解决方案的判断结果(例如通过,错误的答案,时间等),并标记了根本原因(思维级别)错误或错误级别错误)。
如果代码无法p屁股从问题中的样本输入和输出,它标有“样本失败”。
汇编分类和提交问题的结果,比较人类专家的问题解决模式,评估在不同的困难(简单/中/难度)和问题类型(知识/逻辑/逻辑密集型/观察密集型)下的模型性能以及算法推理,样品使用和案例处理中的定位模型。
该团队总共测试了22个大型型号,并提供了完整的性能列表。您可以自己检查每个问题中任何模型提供的解决方案。
同时,绘制了每个模型标记的标记,您可以自由选择要知道的模型。
测试结果显示:
该模型在知识渊博和密集的逻辑问题上发挥更好的作用,并且擅长“旋转记忆”(例如数据结构模板),但在观察或制作案例问题上表现不佳,并且无法处理E“灵感”贪婪的问题和游戏。
与人类相比,诸如O3-Mini之类的模型是GGP表现出更高级的技能准确且没有错误实现,但小于算法设计。
LLM擅长实施问题,但是它们在需要精细算法推理和复杂案例审查的问题上表现不佳,并且经常提供似乎是对但确实错误的解释。
LLMS通常无法正确传递问题提供的输入示例,表明它们不够使用给定信息。
LLM高度取决于工具增强功能(例如终端访问,网络搜索),而不是其自己的推理功能。
该团队还增加了尝试的数量(Pass@k),并发现它可以通过简单的问题显着提高LLM的性能,但他们仍然没有能力抵抗差额的权力。
例如,通过增加O3高模型尝试的数量来尝试其性能,但无论人如何y次测试,它仍然无法解决困难分区的任何问题。
在启用推理功能之后,LLMS通过诸如组合数学之类的密集知识渊博的问题显着改善,但密集观察问题的改善有限。
研究人员还宣布,每个季度,团队将发布全新的审查集,以确保数据及时。
超过一半的团队成员是中国人
Livecodebench Pro团队由一群奥运会冠军组成,其中一半以上是中国成员。
负责该项目的主要人Zheng Zihan毕业于成都外语学校,目前正在纽约大学学习本科学位。他在ICPC世界决赛中代表纽约大学,并获得了第二名。
他曾在Tencent和Nvidia担任实习生和开发实习生,并于今年2月作为实习生进入OpenAI。
另一个负责人Chai Wenhao,2023年在郑安格大学获得了本科学位,并在华盛顿大学学习了硕士学位。今年9月,他将去普林斯顿大学学习博士学位。在计算机科学中。
他曾在亚洲的Pika Labs和Microsoft Research Institute中,他以前的研究主要参与了经常理解和发电模型的视觉效果。
他领导了Moviechat的发展,Moviechat是第一个用于长期视频理解的超大多模式模型。
此外,他发表了有关ICLR,CVPR和ICCV等领先期刊的相关论文研究。
该计划的其他参与者来自加利福尼亚大学,普林斯顿大学等,这是一个非常年轻的团队。
纸张地址:https://arxiv.org/abs/2506.11928
项目地址:https://github.com/gavinzhengoi/livecodebench-pro
兰德列表:https://livecodebenchpro.com/
参考:返回SOHU以查看更多